找到
1
篇与
数据清洗
相关的结果
-
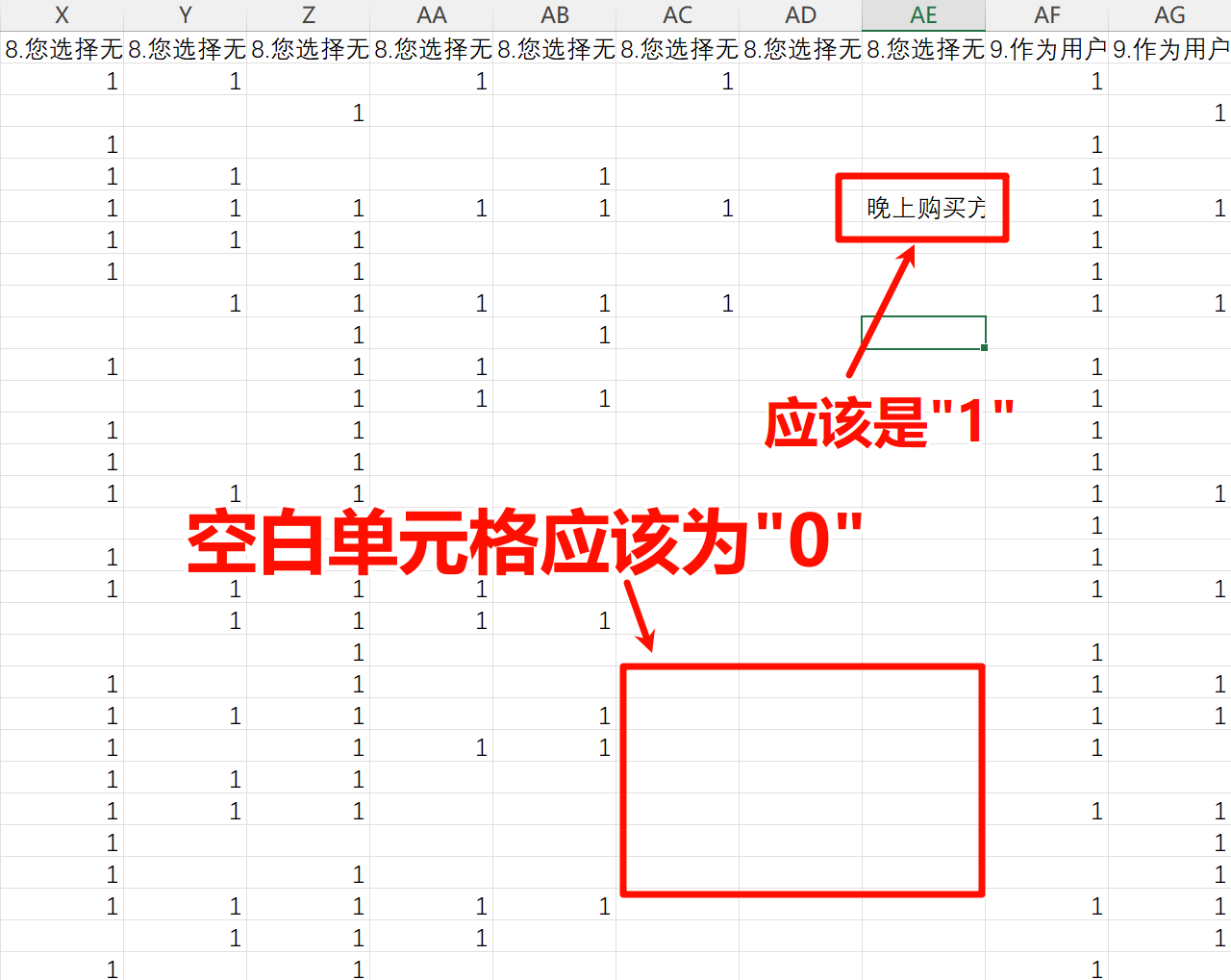
 清洗数据---空值变成0 缘由 因为发现从腾讯问卷导出的数据,多选题格式不正确,不适合导入到SPSS里面做分析。问题主要有: 未选中应该是0,这里为空值。 其他列如果有应该为1,这里直接是填写后的内容。 问题展示: 因此,我通过 Python 代码进行了数据清洗。 使用前准备 重新命名变量:首先需要对变量进行重新命名,例如:Q1、Q2 等,针对多选题,命名为 Q3_1、Q3_2 等。变量名应为变量的英文缩写,例如:感知易用性可以命名为 PEOU1、PEOU2。 将 Excel 文件保存为 CSV 格式。操作步骤如下: 启动 Excel 并打开目标文件。 点击左上角的“文件”菜单。 在菜单中选择“另存为”(有些版本可能会直接显示“保存为”)。 在弹出的对话框中选择保存文件的位置。 在“保存类型”下拉框中选择 CSV(逗号分隔)(*.csv)。 这是已经准备完毕的数据格式示例: 确保 Python 已安装 numpy 和 pandas 库。如果没有,请在命令行终端输入以下命令: pip install numpy pip install pandas 复制文件路径 选中目标文件或文件夹。 按下 Ctrl + Shift + C,将文件或文件夹的完整路径复制到剪贴板。 注意:复制的路径会包含引号,后续需要去除引号。 代码 import pandas as pd # 读取 CSV 文件,将 'input.csv' 替换为你的文件路径,注意去除路径中的引号。 # 例如,若复制路径为 "C:\Users\xcyy5\Desktop\test.csv",则应去掉引号,改为 C:\Users\xcyy5\Desktop\test.csv。 # 注意:代码中的单引号不要更改或删除 df = pd.read_csv(r'input.csv') # 定义需要处理的列范围(从 A 到 B),A 替换为多选题的第一题列名,B 替换为最后一题列名。 # 例如,若我的多选题从第六题到第八题,第八题有 4 个选项,A 替换为 Q6_1,B 替换为 Q8_4。 columns_to_process = df.loc[:, 'A':'B'].columns # 对指定列进行处理:非 1 的值(包括空值)替换为 0 df[columns_to_process] = df[columns_to_process].apply(lambda col: col.apply(lambda x: 1 if x == 1 else 0)) # 保存处理后的结果到新文件,确保汉字正确输出。将 'output.csv' 替换为导出文件的路径。 # 例如,如果想导出到 D 盘的 works 文件夹,并命名为“清洗后-空值为0.csv”,则路径为 D:\works\清洗后-空值为0.csv。 # 注意:代码中的单引号不要更改或删除 df.to_csv(r'output.csv', index=False, encoding='utf_8_sig') print("处理完成,文件已保存!")
清洗数据---空值变成0 缘由 因为发现从腾讯问卷导出的数据,多选题格式不正确,不适合导入到SPSS里面做分析。问题主要有: 未选中应该是0,这里为空值。 其他列如果有应该为1,这里直接是填写后的内容。 问题展示: 因此,我通过 Python 代码进行了数据清洗。 使用前准备 重新命名变量:首先需要对变量进行重新命名,例如:Q1、Q2 等,针对多选题,命名为 Q3_1、Q3_2 等。变量名应为变量的英文缩写,例如:感知易用性可以命名为 PEOU1、PEOU2。 将 Excel 文件保存为 CSV 格式。操作步骤如下: 启动 Excel 并打开目标文件。 点击左上角的“文件”菜单。 在菜单中选择“另存为”(有些版本可能会直接显示“保存为”)。 在弹出的对话框中选择保存文件的位置。 在“保存类型”下拉框中选择 CSV(逗号分隔)(*.csv)。 这是已经准备完毕的数据格式示例: 确保 Python 已安装 numpy 和 pandas 库。如果没有,请在命令行终端输入以下命令: pip install numpy pip install pandas 复制文件路径 选中目标文件或文件夹。 按下 Ctrl + Shift + C,将文件或文件夹的完整路径复制到剪贴板。 注意:复制的路径会包含引号,后续需要去除引号。 代码 import pandas as pd # 读取 CSV 文件,将 'input.csv' 替换为你的文件路径,注意去除路径中的引号。 # 例如,若复制路径为 "C:\Users\xcyy5\Desktop\test.csv",则应去掉引号,改为 C:\Users\xcyy5\Desktop\test.csv。 # 注意:代码中的单引号不要更改或删除 df = pd.read_csv(r'input.csv') # 定义需要处理的列范围(从 A 到 B),A 替换为多选题的第一题列名,B 替换为最后一题列名。 # 例如,若我的多选题从第六题到第八题,第八题有 4 个选项,A 替换为 Q6_1,B 替换为 Q8_4。 columns_to_process = df.loc[:, 'A':'B'].columns # 对指定列进行处理:非 1 的值(包括空值)替换为 0 df[columns_to_process] = df[columns_to_process].apply(lambda col: col.apply(lambda x: 1 if x == 1 else 0)) # 保存处理后的结果到新文件,确保汉字正确输出。将 'output.csv' 替换为导出文件的路径。 # 例如,如果想导出到 D 盘的 works 文件夹,并命名为“清洗后-空值为0.csv”,则路径为 D:\works\清洗后-空值为0.csv。 # 注意:代码中的单引号不要更改或删除 df.to_csv(r'output.csv', index=False, encoding='utf_8_sig') print("处理完成,文件已保存!")