
视频
更多SPSS视频请看:SPSS视频合集地址
描述统计---频率
名词解释
- 百分比:某类别或数值出现的频数占总样本量(含缺失值)的比例,乘以100。
- 有效百分比:某类别或数值出现的频数占有效样本量(排除缺失值)的比例,乘以100。
- 累计百分比:从第一个类别开始,逐层累加各分类的百分比(或有效百分比),反映数据的累积分布。
- 其他:
- 平均值(M):数据总和除以样本量,反映集中趋势,易受极端值影响。
- 中位数(D):数据排序后处于中间位置的值,适用于偏态分布或存在极端值的数据。
- 众数(Q):数据中出现次数最多的值,可能不唯一。
- 总和(S):所有数值的加总结果。
- 标准差(I):衡量数据离散程度,值越大表示数据越分散。
- 最小值(I):数据集中的最小数值,用于识别异常值或数据范围。
- 最大值(×):数据集中的最大数值,与最小值共同定义数据范围。
- 方差(V) :标准差的平方,反映数据偏离均值的平均程度。
- 范围(N):最大值与最小值的差值,体现数据跨度。
- 标准误差平均值(E):样本均值的波动程度,用于估计总体均值的置信区间。
操作
-
分析→描述性统计→频率
-
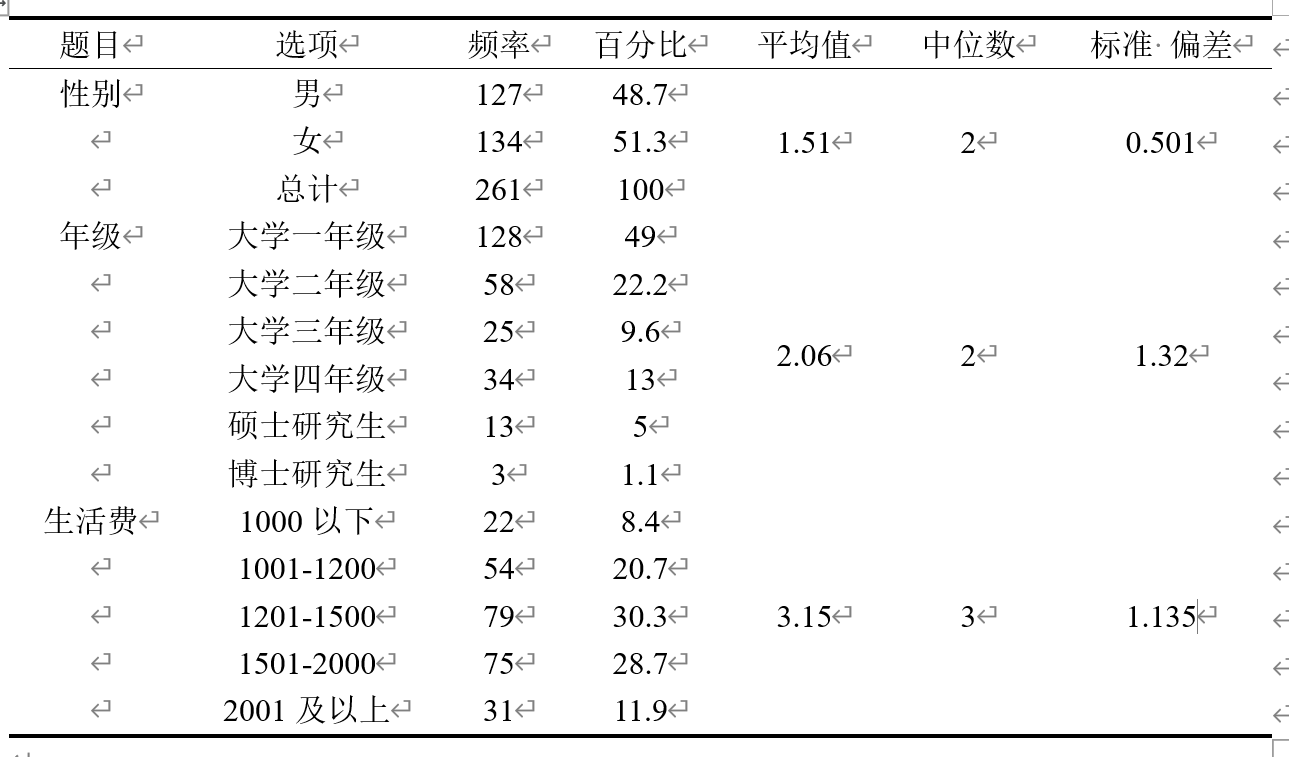
黏贴表格到excel中,为以下格式

-
复制到word里面,制作成三线表然后解释
描述统计---交叉表
前置概念
- 假设要分析“性别”与“吸烟习惯”之间的关系。在交叉表中:
- “性别”会放在 列 位置。
- “吸烟习惯”会放在 行 位置。
- 个案加权:如果一行代表一个个案(人)则不需要,如果代表一类则需要。

名词解释
精确(X)
- 仅渐进法 (A):
- 定义:基于大样本理论的一类统计检验方法,它假设样本量足够大时,统计量的分布趋于某种已知分布(例如正态分布)。这种方法对于样本量较大的情况下特别有效,但在样本量较小的情况下可能不准确。
- 应用:例如,卡方检验和t检验通常都基于渐进理论。渐进方法是通过样本量逐渐增大,来获得近似的结果。
- 蒙特卡洛法 (M):
- 定义:通过随机模拟进行近似计算的统计方法。它通过大量随机样本来估计概率分布、计算期望值、评估检验的显著性等。这种方法非常适合那些难以通过传统解析方法求解的复杂问题。
- 应用:比如,模拟样本数据来估算检验统计量的分布,从而计算p值或显著性水平。
- 置信度级别 (C):
- 定义:指在重复的实验中,构造的置信区间包含未知参数的比例。99%的置信度意味着有99%的概率该区间包含真正的参数值,只有1%的概率区间不包含。
- 应用:例如,如果你在一次实验中得到一个99%的置信区间,那么你可以有99%的信心认为区间包含了总体参数。
- 样本数 ( N):
- 定义:样本数是指在统计实验或调查中所选择的个体数量。在进行假设检验或模拟时,样本量的大小直接影响结果的准确性和稳定性。
- 应用:样本量越大,检验的功效通常越高,能够更好地反映总体特征。
- Fisher精确检验 (E)
- 定义:精确通常指的是在某一特定测试中,估计值与真实值之间的接近程度。在统计检验中,精确度通常与标准误差有关,标准误差越小,估计值的精确度越高。
- 应用:高精度的统计检验能够给出更加准确的结论,减少误差。
- 每个检验的时间限制 (T):
- 定义:这指的是在进行统计检验或模拟时,每次检验的最大允许时间。在一些复杂的计算或模拟中,为了节省计算资源或在实际应用中提高效率,可能会对每个检验的执行时间设定一个上限。
- 应用:对于大型数据集或者复杂模型,可能需要通过设定时间限制来避免计算时间过长,导致程序的停滞。
- 在样本较小或期望频数较低时。
统计(S)
- 卡方检验 (H)
- 定义:常用的检验方法,用于评估两个分类变量之间是否存在统计显著的独立性或相关性。它通过比较观察频数与期望频数之间的差异来进行检验。
- 应用:常用于列联表分析中,检验如性别与某个行为是否相关等问题。
- 相关性 ( R)
- 定义:相关性度量了两个变量之间的线性关系强度和方向。它的值在 -1 和 1 之间,-1 表示完全负相关,1 表示完全正相关,0 表示无关。
- 应用:适用于连续变量之间的关系分析。
- 名义
- 列联系数(Q)
- 用于衡量两个分类变量之间的关系强度。它是基于卡方检验的结果,通过标准化的卡方统计量来计算,表示的是分类变量之间的关联程度。它的值范围是从 0 到 1,0 表示没有关联,1 表示完全关联。
- Phi和克莱姆V
- Phi 系数 (Φ):
- 定义:Phi 系数是一个用于衡量2×2列联表中二分类变量之间关联程度的统计量。它的值范围是 -1 到 1,1:完全正相关,意味着排序完全一致。 -1:完全负相关,意味着排序完全相反。0:无关联,表示排序完全独立。
- 适用情况:通常用于二元分类(2×2列联表),如性别与是否吸烟之间的关系。
- 克莱姆V 系数 (Cramér's V):
- 定义:克莱姆V系数是一个标准化的卡方检验统计量,适用于任何规模的列联表(不仅限于2×2表)。它的值也在0到1之间,0表示没有关联,1表示完全关联。克莱姆V提供了一种衡量变量之间强度的标准化方式,尤其当列联表的维度大于2时。
- 适用情况:适用于多分类变量之间的关系分析,尤其在多类别的情况下,比Phi系数更为常用。
- SPSS 中应用:当选择 Phi和克莱姆V时,SPSS 会同时计算这两个统计量,并根据你的数据规模提供相应的关联强度度量。
- Lambda
- 定义:Lambda 是衡量两个分类变量之间关系强度的一个度量,特别适用于分类变量(名义变量)与因变量(或自变量)之间的关联度。Lambda值的范围是从0到1,值越大,表示变量之间的关联越强。Lambda主要通过计算当知道自变量的值时,因变量的不确定性减少的程度来衡量关系。
- 适用情况:当你需要衡量一个分类自变量对另一个分类因变量的影响强度时,可以选择Lambda。例如,判断教育水平(自变量)对职业类型(因变量)的影响。
- SPSS 中应用:在交叉表分析中勾选 Lambda 后,SPSS 将计算该值,并提供关于自变量与因变量之间关系强度的信息。
- 不确定性系数(U)
- 定义:不确定性系数是一种测量两个分类变量之间依赖关系的度量,源于信息理论。它表示知道一个变量的值时,可以减少另一个变量不确定性的程度。与Lambda类似,它也反映变量之间的依赖关系,但其计算方法基于信息量的减少。通常,不确定性系数的值在0到1之间,值越大,表示依赖关系越强。
- 适用情况:适用于分类数据之间复杂的依赖关系度量,尤其在处理信息不对称或不确定性分析时非常有用。
- SPSS 中应用:在交叉表分析中勾选 不确定性系数 后,SPSS 会计算并展示该值,帮助你衡量两个分类变量之间的依赖关系。
- 列联系数(Q)
- 有序
- Gamma
- 定义:Gamma 是一种用于衡量两个有序分类变量之间关系强度的统计量。它特别适用于对有序数据(如等级评分)进行分析。Gamma 衡量的是变量对之间的排序一致性,即判断一个变量的值与另一个变量值的排序方向是否一致。它的值范围从 -1 到 1。
- 应用:Gamma 系数通常用于有序类别数据的相关性分析,例如学历水平与薪资水平之间的关系,或调查问卷中有序回答选项(如“非常满意”,“满意”,“一般”,“不满意”)的关联。
- SPSS 中应用:勾选 Gamma 后,SPSS 会计算 Gamma 值,以便衡量两个有序分类变量之间的一致性或关联程度。
- 萨默斯d(S)
- 定义:萨默斯 d 是衡量两个有序变量之间关系强度的非对称度量,特别适用于一个变量作为因变量,另一个变量作为自变量的情况。它与 Gamma 类似,但不对称,意味着它考虑了自变量和因变量之间的方向性依赖性。萨默斯 d 衡量的是自变量对因变量的影响强度,值范围从 -1 到 1。
- 应用:萨默斯 d 在有序数据分析中常用于检验自变量对因变量的影响,尤其在需要考虑方向性影响时(例如,分析教育水平对收入水平的影响)。
- SPSS 中应用:当选择 萨默斯 d 时,SPSS 会计算该统计量,帮助你理解一个有序变量如何影响另一个有序变量的变化。
- 肯德尔tau-b
- 定义:肯德尔 tau-b 是衡量两个有序变量之间相关性的统计量,适用于有序类别数据,特别是在数据中存在并列(ties)的情况下。它通过计算一致对(concordant pairs)和不一致对(discordant pairs)之间的比例来衡量相关性。tau-b 是一种调整了并列值的相关性度量,适用于列联表较大的情况。
- 应用:tau-b 适用于有序数据(如调查问卷中的等级评分)分析,并能够处理并列值(例如两个项目评分相同的情况)。
- SPSS 中应用:在 SPSS 中勾选 肯德尔 tau-b 后,SPSS 会计算 tau-b 值,并提供关于两个有序变量之间相关性强度的详细信息。
- 肯德尔 tau-c
- 定义:肯德尔 tau-c 是另一种衡量有序变量相关性的统计量,类似于 tau-b,但它用于更大规模的列联表,尤其是在列联表的行和列数量不相等的情况下。tau-c 也是基于一致对和不一致对的计算,并且它更适合处理大型表格。其值范围也从 -1 到 1,表示两个变量之间的排序一致性。
- 应用:tau-c 特别适用于当列联表的维度较大时,如分析调查问卷中多个有序选项的关联。
- SPSS 中应用:在 SPSS 中勾选 肯德尔 tau-c 后,SPSS 会计算 tau-c 值,并提供关于较大规模列联表中的有序数据相关性的度量。
- Gamma
- 按区间标定
- Eta:
- 定义:用来评估 分类变量(如性别、教育水平、治疗组等) 和 连续变量(如收入、分数、时间等) 之间的关系。在交叉表分析时,如果选择了 Eta,SPSS 会计算并报告分类变量对连续变量的影响程度。帮助研究人员理解自变量的效应有多大.
- Eta:
- Kappa
- 定义:Kappa系数用于衡量两名观察者或两种测量工具之间的一致性,排除随机性因素的影响。它衡量的是超出随机一致性的协议程度,常用于检验分类数据中的一致性。
- **风险(I) **
- 用于衡量某事件发生的概率,常用于流行病学分析。
- **麦克尼马尔(M) **
- 定义:柯克兰和曼特尔-亨塞尔检验用于分析两个分类变量之间的关系,同时控制其他可能的混杂变量。该检验通过调整控制变量的影响,帮助检验两个分类变量之间的独立性或关联性。
- 应用:通常用于流行病学研究中,评估控制混杂变量后,暴露与疾病之间的关联是否显著。例如,在控制年龄、性别等因素后,检验吸烟与肺癌之间的关系。
- **柯克兰和曼特尔-亨塞尔统计(A) **
- 检验一般比值比等于(T):在交叉表分析中勾选 检验一般比值比等于1 后,SPSS 会进行假设检验,检验比值比是否等于1,帮助判断两个变量之间的关系是否显著。
单元格(E)
- 计数(T):
- 实际(O):选择实际的计数数据进行分析。
- 期望(E):选择期望值进行分析,通常用于卡方检验中期望的频率值。
- 隐藏最小的计数(H):在计算计数时,隐藏小于指定值的计数。
- 小于5:指的是将计数小于5的观察数据隐藏,通常用于频次表分析中,以避免过小的频数影响结果。
- z检验:
- 比较列比例(P):进行列比例比较,常用于检验两个比例是否有显著差异。
- 调整p值(邦弗瑞尼法):这是一种多重比较校正方法,主要用于减少因进行多次假设检验而导致的错误拒绝率。
- 百分比:
- 行(R):对行的百分比进行计算,通常用于交叉表分析中。
- 列(C):对列的百分比进行计算,也用于交叉表分析。
- 总计(T):对整个数据集的百分比进行计算。
- 残差:
- 未标准化(U):不进行标准化的残差。
- 标准化(S):标准化后的残差,使得残差值的尺度统一。
- 调整后标准化(A):通过某种方法调整后计算的标准化残差,通常用于多重比较。
- 非整数量重:
- 单元格计数四舍五入(N):对单元格计数进行四舍五入处理。
- 个案权重四舍五入(W):对个案权重进行四舍五入处理。
- 截断单元格计数(L):截断单元格计数,不进行四舍五入。
- 截断个案权重(W):对个案权重进行截断。
步骤
- 选择交叉表
- 在SPSS菜单中,选择 “分析”→ “描述统计”→ “交叉表”。
- 选择变量
- 在交叉表对话框中,选择你要分析的两个变量:
- 将一个变量拖到 “行” 框中。
- 将另一个变量拖到 “列” 框中。
- 独立性检验
- 点击 “统计”(S)按钮,在弹出的对话框中勾选 “卡方”(H):
- 进行独立性检验,检验这两个变量是否独立。SPSS 会通过卡方检验来判断行和列变量之间是否有显著的统计关系。
- 点击 “统计”(S)按钮,在弹出的对话框中勾选 “卡方”(H):
- 选择单元格显示
- 点击 “单元格”(Cells)按钮,选择你希望在交叉表中显示的信息:
- 勾选 “观察频数”(Observed Count),以显示每个单元格的实际观测频数。
- 勾选 “期望频数”(Expected Count),以显示每个单元格的期望频数(如果变量之间没有关联时的频数)。
- 还可以勾选 “列百分比”、“行百分比” 或 “总百分比” 来显示不同的百分比数据。
- 点击 “单元格”(Cells)按钮,选择你希望在交叉表中显示的信息:
- 执行检验
- 设置完所有选项后,点击 “确定”(OK)按钮,SPSS 会计算交叉表并输出结果。
- 查看输出结果
- SPSS 会生成一个交叉表,并在 卡方检验 结果中提供如下输出:
- 卡方统计量:卡方值(H)、自由度(df)和 p 值(p-value)。
- 如果 p 值小于显著性水平(例如,0.05),则拒绝原假设,认为这两个变量之间存在显著的关联性。反之,如果 p 值大于显著性水平,则接受原假设,认为这两个变量是独立的。
- 解读结果
- 卡方值:反映了观察到的频数与期望频数之间的差异。值越大,表明差异越显著。
- 自由度:= (行数 - 1) × (列数 - 1)
- p值:
- p < 0.05:拒绝原假设,认为变量之间有显著关系。
- p >= 0.05:接受原假设,认为变量之间没有显著关系。
多重响应---多选题分析
名词解释
百分比与个案百分比
百分比:
$$ \text{百分比} = \frac{\text{个案数}}{\text{所有选择的总次数}} \times 100\% $$个案百分比:
$$ \text{个案百分比} = \frac{\text{个案数}}{\text{总样本数}} \times 100\% $$单元格百分比
- 行(W):以“行变量”的总数为基准计算百分比。
适用场景:分析不同行群体在列变量上的分布。 - 列(C):以“列变量”的总数为基准计算百分比。
适用场景:分析不同列选项在行变量中的占比。 - 总计(T):以总样本量或总响应数为基准计算百分比。
适用场景:全局视角下各单元格的占比。 - 在响应集之间匹配变量(M):当分析两个多选题时,强制SPSS按同一批样本(即“完全配对”)计算交叉表。
- 使用场景:确保两个多选题的样本完全一致(避免因缺失值导致样本量波动)。
- 示例:分析“购买渠道”和“退货原因”的关系时,仅保留同时回答了这两个问题的样本。
百分比基于
- 个案(S):分母为总样本数(即每个受访者计为1)。
适用场景:关注“人群比例”(如“多少人同时选了A和B”)。 - 响应(R):分母为总响应数(即每个受访者的多选答案分开计算)。
适用场景:关注“答案比例”(如“所有答案中,A和B的占比”)。 示例:
若100人中,每人平均选2个购买渠道(总响应=200次):
- 基于个案:某渠道被选中的比例 = 选中人数 / 100
- 基于响应:某渠道被选中的比例 = 选中次数 / 200
缺失值
- 在二分集内成列排除个案(E):若某受访者在多选题中存在缺失值(如未回答某选项),则在整个分析中排除该受访者。
影响:样本量减少,但保证所有分析基于完整数据。 - 在类别内成列排除个案(X):仅在当前分析的分类变量(如性别)存在缺失值时排除个案,多选题的缺失值不影响。
影响:样本量相对保留更多。
步骤
- 设置多重响应变量
- 选择 “分析”(Analyze) > “多重响应”(Multiple Response) > “定义多重响应集”(Define Variable Sets)。
- 在弹出的对话框中:
- 选择响应变量:在 “变量列表” 中选择与多选题相关的所有变量。例如,选择“苹果”、“香蕉”和“橙子”。
- 点击箭头,将这些变量添加到 “响应变量” 框中。
- 选择一个编码方式:
- 二分法(D)(计数值(0):1。1表示选择,0表示未选择)是最常用的方式。
- 为响应变量设置一个 “组名”,例如 "喜欢的水果"。
- 点击 “添加”,然后点击 “继续”。
- 进行频率分析
- 完成多重响应集的设置后,你可以分析各个选项的选择频率。
- 选择 “分析”(Analyze) > “多重响应”(Multiple Response) > “频率”(Frequencies)。
- 进行交叉表分析
- 选择择 “分析”(Analyze) > “多重响应”(Multiple Response) > “交叉表”(Crosstabs)
- 文件 >新建 >数据
- 复制交叉表结果,在excel里面修改为以下格式,黏贴选择“与变量名称一起粘贴(A)”:
- 数据 >个案加权 >个案加权依据(W) >频率变量(E):频数
- 选择 “分析”(Analyze) > “描述统计”(Descriptive Statistics) > “交叉表”(Crosstabs)。
- 行变量:选择你希望与多重响应集分析的变量(例如,性别)。
- 列变量:选择多重响应集(例如“喜欢的水果”)。
- 点击 “统计量”(Statistics)按钮,选择 “卡方”(Chi-square)或其他相关统计量。
- 点击 “单元格”(Cells)按钮,选择是否显示 “观察频数”、“期望频数” 和 “百分比”。
- 选择择 “分析”(Analyze) > “多重响应”(Multiple Response) > “交叉表”(Crosstabs)





